Introduction
The internet has lots of incivil language use since the age of forums. This blog post basically uses a pre trained language model to detect incivil languages in the internet posts like tweets and comments. This blog contains 2 different approaches, simple and multi domain. In the simple approach, the model is fine tuned to binary classify incivil language in the dataset. In multi domain approach, the datasets from multiple domains are used to make the model more robust for detecting incivil language bits from different domains. Usually in text classification blogs, fine tuning in one domain is being explained. What makes this blog post unique is that not only it explains fine tuning, it also explains how and why multi domain approach is used. The tool in this blog post can only be used for English language. The original paper can be found here.
Task
Incivil language detection is basically a text classification task in NLP. The input is a piece of text, the output is a label. In the case of binary classification, the label is either 0 (no incivility) or 1 (yes incivility). In the case of multi label classification (not in this blog post, but in the shared paper), the output is a binary vector where ith element of the vector is 1 if the given input contains ith type of incivility (namecalling, vulgarity, threat etc.). The function to be aimed to learn in this task is h(repr(x)) = y. repr(x) is a tensor representing the input(a series of word vectors), y is the output vector.
Simple Approach
- 1 classifier is fine-tuned on the training data of each domain, then evaluated on test data of its own domain
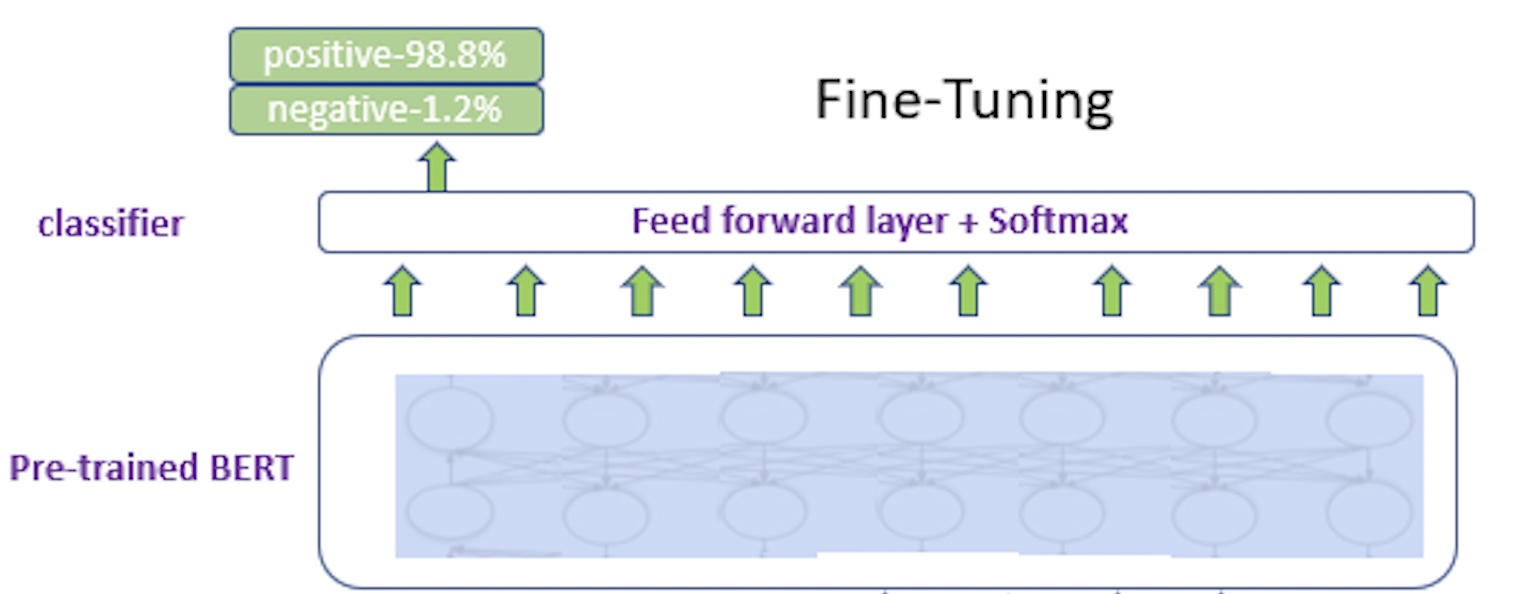
Language model based transfer learning is the basis for all the work in this blog post. Due to its huge impact in transfer learning in NLP, BERT has been used. Simple approach is basically fine tuning BERT. BERT is taken and a fully connected layer on top of it is added. That fully connected layer has a softmax layer that will give the binary classification prediction. The image below is a summary. We can think of the outcome positive as incivility exists, negative as incivility does not exist.
Multi Domain Approach
- 1 classifier is fine-tuned on the combined training data from different domains, then evaluated on test data of each domain
This approach is based on simple approach, but using multiple datasets from different domains. Multidomain approach is also based on transfer learning with pre-trained language model. The goal is to research how dataset characteristics and annotation differences affects the robustness of the predictions when the datasets are used together. Domain can affect the content and the quality of the data.
Some hypothetical domain examples to make the word “domain” clearer:
- 3 datasets about same topic (i.e. racism): one of them consists of tweets from Twitter, one of them consists of posts from Facebook, one of them consists of comments from a white supremacist forum. Each of the datasets represent a domain because even if the topic is same, the samples will be different based on:
- each platform has its own slang/lingo
- user groups have different backgrounds
- 2 datasets from same platform (i.e. twitter): one of them is about namecalling, other one is about misogyny. Each of them represent a domain based on:
- namecalling can contain common misogyny terms but not necessarily
- misogyny can contain common namecalling terms but not necessarily
The idea is that if we use datasets together, the classifier will benefit from variety of samples and robustness will increase. For example, twitter dataset has several samples that is actually racist, but the slang used in these samples is not commonly seen in the majority of the twitter dataset. Let’s say that particular slang exists in facebook and/or forum datasets. When the classifier is trained in all of the datasets, meaning the classifier is exposed to that particular slang more than the twitter data has, and when the classifier is tested on twitter dataset, it’s expected that its chances to detect that particular racist samples will increase.
Data
Local news comments
A collection of comments taken from local news website. Following labels are used as classes:
- aspersion
- lying accusation
- name-calling
- pejorative
- vulgarity
Local Politics Tweets
A collection of microblog posts from the Twitter accounts of the local politicians. Only one label is used as class:
- name-calling
Russian troll Tweets
A small subset of the 3 million English Tweets written by Russian trolls. Only one label is used as class:
- name-calling
Since only 1 label (name-calling) is common in all 3 datasets, first dataset is adjusted to be used only for name-calling label. Some name-calling examples:
"You pathetic, pimple-faced little adolescent moron. Have you not studied sarcasm yet? \n\nLet me guess...you are a product of home schooling, right?"
"Canada doesn’t need another CUCK! We already have enough #LooneyLeft #Liberals f**king up our great country! #Qproofs #TrudeauMustGo"
"if yo girl doesnt swallow kids, that bitch basic!"
And some civil examples which does not have name-calling:
"im genuinely getting mad at this children's video game about mickey mouse and darkness and big keys"
"please advice about Bank nifty & how the NPA will benefit for PSU Banks ?"
"Strawberry Swing As an editor with a history of personal attacks and of creating attack pages, I disagree that it wasn't appropriate."
Data can be provided upon request from Steven Bethard from University of Arizona Information Department.
Application
In this section, I gave some reproducible examples. After reading this section, go to results section to see the hyperparameters I used and the results I got with those exact hyperparameters.
Source Code
The source code is used from for a version (0.6.1) of transformers repository. My modified version of the original code can be found from my own repository. transformers repository from huggingface and its dependencies according to version are publicly available for its versions on here.
Training and Evaluation
Once you clone the repository, only run_classifier_custom.py file is enough. The command should specify following parameters:
- train_dir
- eval_dir
- bert_model: for fine tuning, use bert-base, for using already fine tuned model (multi domain approach), give the directory of said model
- task_name: give sst-2
- output_dir
- cache_dir
- max_seq_length: try 128 or 256
- train_batch_size: try 16, 32, 64 or 128
- learning_rate: try 8e-6, 2e-5, 4e-5 or 8e-5
- num_train_epochs: try 2, 3, 4, 5, 6 or 8
- do_train: if you are training, include this in the command
- do_eval: if you are gonna do evaluation, include this in the command
This is basically fine tuning a language model by adjusting it to a binary classification task (sst-2) for a specific domain (see data section). As explained in the approach sections, you can use different datasets by adjusting train-dev-test combinations. Some examples you can reproduce:
- use train and dev data of domain A (e.g. Russian troll Tweets), find your best model, evaluate it on test data of domain A (e.g. Russian troll Tweets), to do simple approach.
- use do_train and do_eval
- combine train and dev data of domains A (e.g. Russian troll Tweets), B (e.g. Local Politics Tweets) and C (e.g. Local news comments), find your best model by using dev data, evaluate it on test data of a domain (e.g. Local news comments), to inspect multi domain approach.
- use do_train and do_eval
Some details from code
The tokenizer is loaded from the bert model we specified.
tokenizer = BertTokenizer.from_pretrained(args.bert_model, do_lower_case=args.do_lower_case)
The model is loaded from the bert model we specified.
model = BertForSequenceClassification.from_pretrained(args.bert_model,
cache_dir=cache_dir,
num_labels = num_labels)
The optimizer is set as adam optimizer.
optimizer = BertAdam(optimizer_grouped_parameters,
lr=args.learning_rate,
warmup=args.warmup_proportion,
t_total=num_train_optimization_steps)
The trained model is saved with weights and configuration information.
# Save a trained model and the associated configuration
model_to_save = model.module if hasattr(model, 'module') else model # Only save the model it-self
output_model_file = os.path.join(args.output_dir, WEIGHTS_NAME)
torch.save(model_to_save.state_dict(), output_model_file)
output_config_file = os.path.join(args.output_dir, CONFIG_NAME)
with open(output_config_file, 'w') as f:
f.write(model_to_save.config.to_json_string())
The results are calculated with the function acc_prec_recall_f1.
result = acc_prec_recall_f1(preds, out_label_ids)
The results are written with these lines:
with open("preds_labels.txt","w") as writer2:
writer2.write("preds_labels\n")
for pred, label in zip(preds, out_label_ids):
line = str(pred) + " " + str(label) + '\n'
writer2.write(line)
Results
In the results, f1 score is considered. Here, the results were obtained with the models that has following hyperparameters.
- max_seq_length: 256
- train_batch_size: 64
- learning_rate: 4e-5
- num_train_epochs: 4
| Approach | Local news comments | Russian troll Tweets | Local politics Tweets |
|---|---|---|---|
| single | 0.57 | 0.65 | 0.70 |
| multi-domain | 0.65 | 0.81 | 0.80 |
Important note: For single, train-dev-test data is from each domain. For multi-domain, train-dev data is from all domains combined, test data is from each domain.
As you can see from the table, the multi-domain approach performed better on each domain in comparison to simple approach which only uses 1 domain.
Conclusion
In this blog post, BERT is applied with single-domain and multi-domain approaches for an incivility detection task. The approaches have been explained, task has been defined in detail, data has been explained with examples, source code has been shared with versions, some significant parts of the code has been explained in snippets, results have been given, and the hyperparameters to recreate the experiments and how to access the data have been explained. Thank you for reading!